Muse Image and Video
In Meta AI Blog, 2026
Meta’s first in-house image and video generation models, with agentic reasoning, ranking #2 on Arena leaderboards.
Research Scientist · AMI Labs
I am a Research Scientist at AMI Labs. My current research focuses on multimodal understanding, generation and world modeling. I obtained a PhD from Carnegie Mellon University (here’s a link to my dissertation), where I worked on learning from and understanding videos. I was previously part of the Meta Superintelligence Labs (MSL) and Facebook AI Research (FAIR) at Meta, and have spent time at DeepMind, Adobe and Facebook as an intern. See here for a formal bio.
After 7 incredible years, I have moved from Meta to AMI Labs! See more here.
Mark Zuckerberg announced Muse Image and Muse Video, the first image/video generation models from Meta Superintelligence Labs, ranked 2nd on multiple Arena evals. I drove key efforts in multi-image editing.
EgoVis 2023-24 Distinguished Paper Award for HierVL.
Mark Zuckerberg announced Llama 3.1, along with our state-of-the-art video recognition capabilities!
Invited panelist for the AI for Content Creation (AI4CC) workshop at CVPR 2024 (along with Cynthia Lu and Robin Rombach).
LaViLa and Ego4D among the winners of the EgoVis 2022-23 Distinguished Paper Awards!
Presented Emu Video at RunwayML’s inaugural Research and Art (RNA) event.
Invited judge for the MIT Filmmaking Hackathhon 2024.
Mark Zuckerberg announced our state-of-the-art video generation work, Emu Video! Also see coverage by TechCrunch, TheVerge, VentureBeat, Reuters, and others!
Giving a talk at HVU Workshop and presenting 5 papers at CVPR 2023!
Mark Zuckerberg announced our multimodal embedding work, ImageBind! Also see coverage by TheVerge, Engadget, SiliconANGLE, maginative and others!
Presenting 3 papers at CVPR 2022, including Omivore, a single model that obtains state-of-the-art results across 3 different modalities: images, videos and single-view 3D!
We announced Ego4D, the largest egocentric video dataset to date! See this video for a quick intro, and see coverage from TechCrunch, TheVerge, Axios, Fast Company, and others!
2026 — Present
Research Scientist · New York
Building world models that understand real-world sensor data. Research on multimodal understanding, generation and world modeling.
2019 — 2026
Research Scientist · New York
Core contributor to Meta’s media generation and multimodal efforts, including Movie Gen, Muse Image, Emu Video, ImageBind and Llama 3. Earlier at FAIR, worked on self-supervised, multimodal and omnivorous representations for video understanding.
In Meta AI Blog, 2026
Meta’s first in-house image and video generation models, with agentic reasoning, ranking #2 on Arena leaderboards.
In Meta AI & Instagram Edits, 2026
Text-prompted, high-fidelity video edits in under 30 seconds — local edits, scene transformations, and composite requests.
In ICML, 2025
Pure text-only LLMs can use off-the-shelf multimodal embedding models to do various multimodal tasks!
In arXiv, 2024
State-of-the-Art Video (+Audio) Generation Model
In arXiv, 2024
State-of-the-Art open-source LLM with multimodal capabilities
In ECCV, 2024
A simple and effective approach to high-quality video generation by learning to animate high quality images.
In CVPR, 2023 (Highlighted Presentation)
One embedding space for 6 different modalities, enables zero-shot recognition on all modalities!
In CVPR, 2023 (Highlighted Presentation)
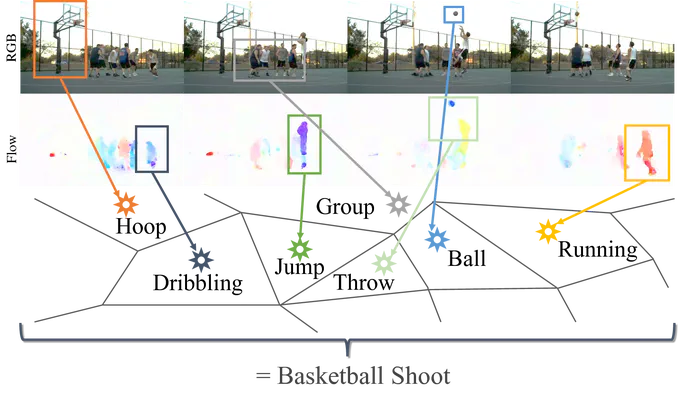
Leveraging LLMs to auto-annotate videos for representation learning.
In CVPR, 2022 (Oral Presentation)
A single model for images, video and single-view 3D.
In CVPR, 2022 (Best paper finalist)
The largest egocentric video dataset.
In CVPR, 2022
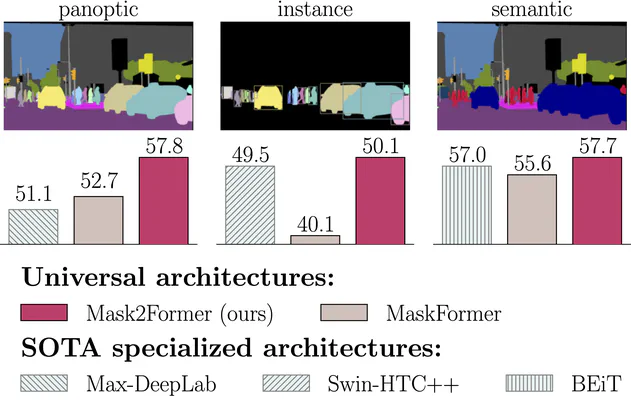
Single architecture state-of-the-art in instance, semantic and panoptic segmentation.
In ICCV, 2021
An autoregressive video transformer architecture for action anticipation in videos.
Summer 2018
Research Scientist Intern · London
Worked with Andrew Zisserman, João Carreira and Carl Doersch on attention-based architectures for recognizing and localizing human actions in video.
In CVPR, 2019 (Oral Presentation)
Among the first applications of Transformers to model videos. SOTA results: close 2nd at AVA Challenge, CVPR'18.
Summer 2017
Research Scientist Intern · Menlo Park
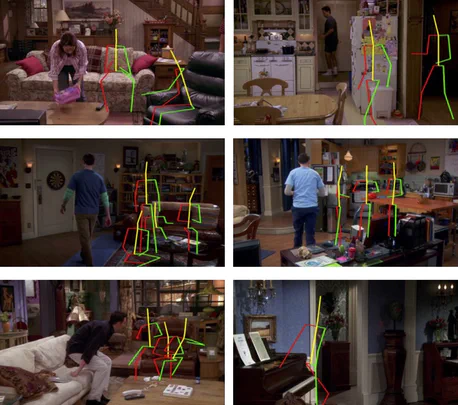
Worked with Lorenzo Torresani, Georgia Gkioxari and Du Tran on detecting and tracking people for keypoint estimation in video.
In CVPR, 2018
Human keypoint tracking approach that ranked first in ICCV 2017 PoseTrack keypoint tracking challenge!
Summer 2016
Research Scientist Intern · San Francisco
Worked with Josef Sivic and Bryan Russell on learnable spatio-temporal aggregation for action classification.
In CVPR, 2017
Aggregating visual features for action recognition.
2014 — 2019
PhD in Robotics · Pittsburgh
PhD with Deva Ramanan on learning from and understanding videos; MS with Martial Hebert, Abhinav Gupta, Kris Kitani and David Fouhey as a Siebel Scholar.
In ICLR, 2020 (Oral Presentation)
A dataset to evaluate temporal reasoning in video models.
In NeurIPS, 2017
Among the first applications of attention for contemporary video/action understanding.
In CVPR, 2017 (Spotlight Presentation)
Learning how humans interact with their environment by watching TV.
In ECCV, 2016 (Spotlight Presentation)
A single embedding space, good for both generating and understanding 3D models
Summer 2013
Software Engineering Intern · Menlo Park
First stint at Facebook, working on Graph Search.
2010 — 2014
B.Tech in Computer Science · Hyderabad, India
Undergraduate research with C. V. Jawahar at CVIT on large-scale image retrieval and computer vision.