ActionVLAD: Learning spatio-temporal
aggregation for action classification
|
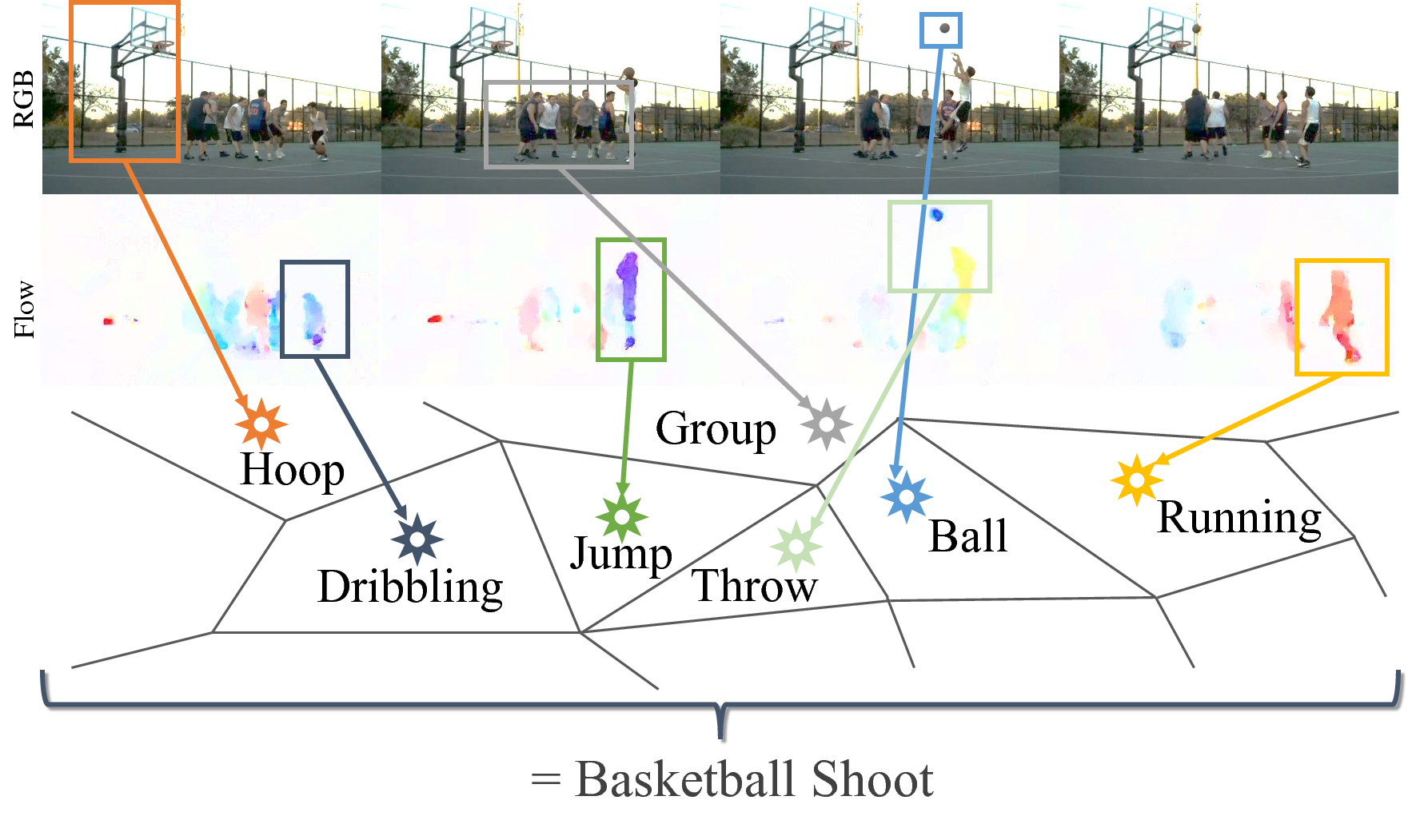
| In this work, we introduce a new video representation for action classification that aggregates local convolutional features across the entire spatio-temporal extent of the video. We do so by integrating state-of-the-art two-stream networks with learnable spatio-temporal NetVLAD codebooks. The resulting architecture is end-to-end trainable for whole-video classification. We investigate different strategies for pooling across space and time and combining signals from the different streams. We find that (i) it is important to pool jointly across space and time, but (ii) appearance and motion streams are best aggregated into their own separate representations. Finally, we show that our representation outperforms the two-stream base architecture by a large margin (13% relative) as well as outperforms other baselines with comparable base architectures on HMDB51, UCF101 and Charades video classification benchmarks. |
People
 Rohit Girdhar |
 Deva Ramanan |
 Abhinav Gupta |
 Josef Sivic |
 Bryan Russell |
Paper

|
R. Girdhar, D. Ramanan, A. Gupta, J. Sivic and B. Russell ActionVLAD: Learning spatio-temporal aggregation for action classification In Proc. of Conference on Computer Vision and Pattern Recognition (CVPR), 2017 [arXiv] [code/models] [supplementary video] [poster] [BibTex] |
Acknowledgements
The authors would like to thank Gul Varol and Gunnar Atli Sigurdsson for help with iDT. DR is supported by NSF Grant 1618903, Google, and the Intel Science and Technology Center for Visual Cloud Systems (ISTC-VCS).