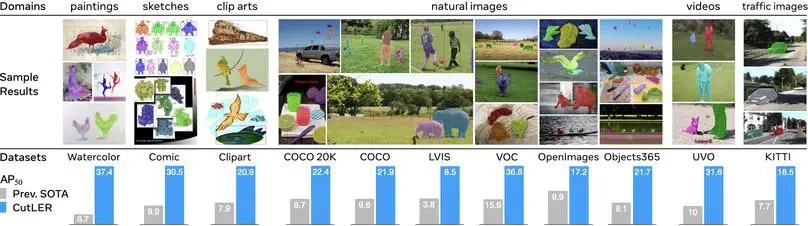
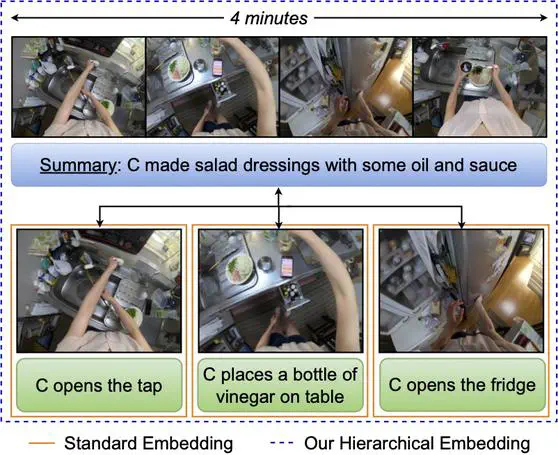
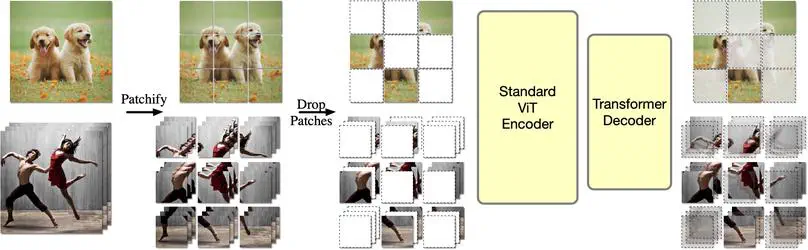
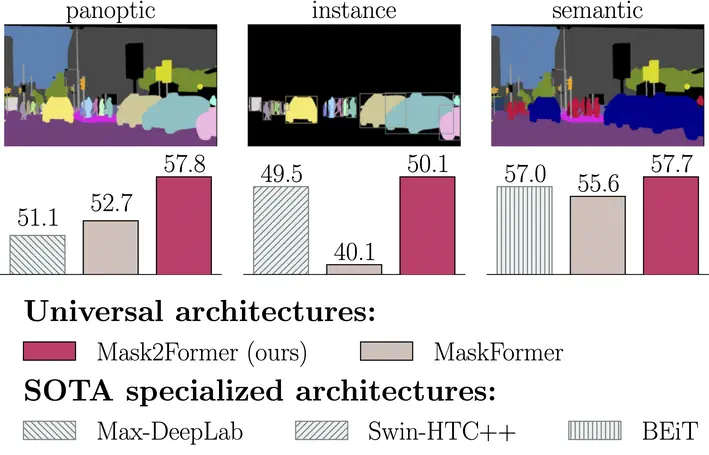
I am a Research Scientist at the Meta Superintelligence Labs. My current research focuses on understanding and generating multimodal data. I obtained a PhD from Carnegie Mellon University (here’s a link to my dissertation), where I worked on learning from and understanding videos. I was previously part of the Facebook AI Research (FAIR) group at Meta, and have spent time at DeepMind, Adobe and Facebook as an intern. See here for a formal bio.
News
-
Jun 2025
EgoVis 2023-24 Distinguished Paper Award for HierVL.
-
Oct 2024
Mark Zuckerberg announced our work on MovieGen, the new state-of-the-art media generation and editing system, outperforming SORA, Emu Video and more! Covered in NY Times, FT, Forbes, WIRED, Bloomberg, TechCrunch, etc.
-
Jul 2024
Mark Zuckerberg announced Llama 3.1, along with our state-of-the-art video recognition capabilities!
-
Jun 2024
Invited panelist for the AI for Content Creation (AI4CC) workshop at CVPR 2024 (along with Cynthia Lu and Robin Rombach).
-
Jun 2024
LaViLa and Ego4D among the winners of the EgoVis 2022-23 Distinguished Paper Awards!
-
Apr 2024
/animatefunctionality based on Emu Video is publicly released! Try it out to animate images generated using/imagineon meta.ai! -
Apr 2024
Presented Emu Video at RunwayML’s inaugural Research and Art (RNA) event.
-
Feb 2024
Invited judge for the MIT Filmmaking Hackathhon 2024.
-
Nov 2023
Mark Zuckerberg announced our state-of-the-art video generation work, Emu Video! Also see coverage by TechCrunch, TheVerge, VentureBeat, Reuters, and others!
-
Jun 2023
Giving a talk at HVU Workshop and presenting 5 papers at CVPR 2023!
-
May 2023
Mark Zuckerberg announced our multimodal embedding work, ImageBind! Also see coverage by TheVerge, Engadget, SiliconANGLE, maginative and others!
-
Jun 2022
Presenting 3 papers at CVPR 2022, including Omivore, a single model that obtains state-of-the-art results across 3 different modalities: images, videos and single-view 3D!
-
Oct 2021
We announced Ego4D, the largest egocentric video dataset to date! See this video for a quick intro, and see coverage from TechCrunch, TheVerge, Axios, Fast Company, and others!
-
PhD in Robotics, 2019
Carnegie Mellon University, Pittsburgh PA
-
MS in Robotics, 2016
Carnegie Mellon University, Pittsburgh PA
-
B. Tech. in Computer Science, 2014
IIIT Hyderabad, India
-
Meta · Research Scientist
New York · 2019 -- Present
-
DeepMind · Research Scientist Intern
London · Summer 2018
-
Facebook · Research Scientist Intern
Menlo Park · Summer 2017
-
Adobe · Research Scientist Intern
San Francisco · Summer 2016
-
Facebook · Software Engineering Intern
Menlo Park · Summer 2013
Highlights
Videos powered by MovieGen and Emu Video!