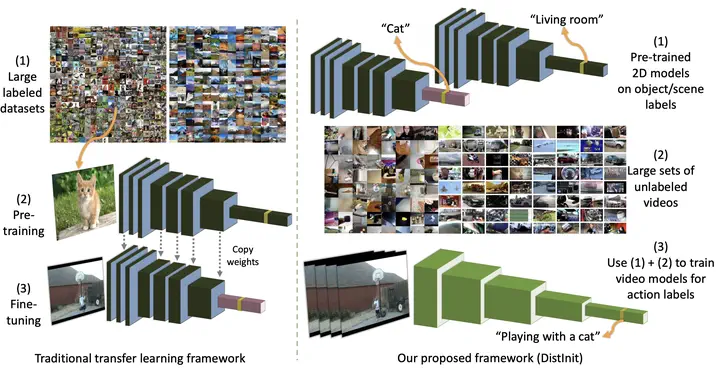
Video recognition models have progressed significantly over the past few years, evolving from shallow classifiers trained on hand-crafted features to deep spatiotemporal networks. However, labeled video data required to train such models have not been able to keep up with the ever-increasing depth and sophistication of these networks. In this work, we propose an alternative approach to learning video representations that require no semantically labeled videos and instead leverages the years of effort in collecting and labeling large and clean still-image datasets. We do so by using state-of-the-art models pre-trained on image datasets as “teachers” to train video models in a distillation framework. We demonstrate that our method learns truly spatiotemporal features, despite being trained only using supervision from still-image networks. Moreover, it learns good representations across different input modalities, using completely uncurated raw video data sources and with different 2D teacher models. Our method obtains strong transfer performance, outperforming standard techniques for bootstrapping video architectures with image-based models by 16%. We believe that our approach opens up new approaches for learning spatiotemporal representations from unlabeled video data.
Rohit Girdhar
Research Scientist
My current research focuses on understanding and generating multimodal data