Binge Watching: Scaling Affordance Learning from Sitcoms
In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017 (Spotlight Presentation)
Abstract
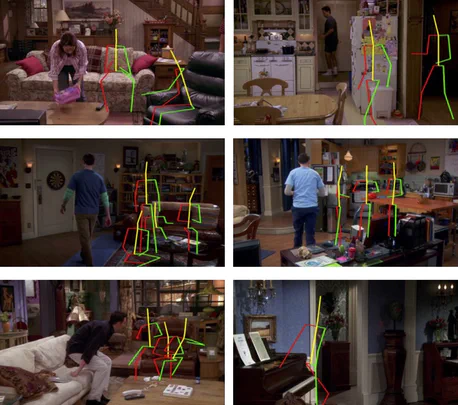
In recent years, there has been a renewed interest in jointly modeling perception and action. At the core of this investigation is the idea of modeling affordances(Affordances are opportunities of interaction in the scene. In other words, it represents what actions can the object be used for). However, when it comes to predicting affordances, even the state of the art approaches still do not use any ConvNets. Why is that? Unlike semantic or 3D tasks, there still does not exist any large-scale dataset for affordances. In this paper, we tackle the challenge of creating one of the biggest dataset for learning affordances. We use seven sitcoms to extract a diverse set of scenes and how actors interact with different objects in the scenes. Our dataset consists of more than 10K scenes and 28K ways humans can interact with these 10K images. We also propose a two-step approach to predict affordances in a new scene. In the first step, given a location in the scene we classify which of the 30 pose classes is the likely affordance pose. Given the pose class and the scene, we then use a Variational Autoencoder (VAE) to extract the scale and deformation of the pose. The VAE allows us to sample the distribution of possible poses at test time. Finally, we show the importance of large-scale data in learning a generalizable and robust model of affordances.
Citation
@inproceedings{girdhar2016learning,
title = {Binge Watching: Scaling Affordance Learning from Sitcoms},
author = {Wang, Xiaolong and Girdhar, Rohit and Gupta, Abhinav},
booktitle = {CVPR},
year = {2017},
}