Rohit Girdhar
Rohit Girdhar
Home
Projects
Light
Dark
Automatic
Publications
Type
Conference paper
Paper-Journal
Date
2025
2024
2023
2022
2021
2020
2019
2018
2017
2016
LLMs can see and hear without any training
Pure text-only LLMs can use off-the-shelf multimodal embedding models to do various multimodal tasks!
Kumar Ashutosh
,
Yossi Gandelsman
,
Xinlei Chen
,
Ishan Misra
,
Rohit Girdhar
PDF
Cite
Code
Diffusion Autoencoders are Scalable Image Tokenizers
Simplified image tokenization using diffusion
Yinbo Chen
,
Rohit Girdhar
,
Xiaolong Wang
,
Sai Saketh Rambhatla
,
Ishan Misra
PDF
Cite
Code
MotiF: Making Text Count in Image Animation with Motion Focal Loss
Using flow to improve motion in video generation
Shijie Wang
,
Samaneh Azadi
,
Rohit Girdhar
,
Saketh Rambhatla
,
Chen Sun
,
Xi Yin
PDF
Cite
Movie Gen: A Cast of Media Foundation Models
State-of-the-Art Video (+Audio) Generation Model
MovieGen team (core-contributor)
PDF
Cite
Video
The Llama 3 Herd of Models
State-of-the-Art open-source LLM with multimodal capabilities
Llama3 team (co-lead the video recognition efforts)
PDF
Cite
Code
SoundingActions: Learning How Actions Sound from Narrated Egocentric Videos
Self-supervised embedding to learn how actions sound from narrated in-the-wild egocentric videos.
Changan Chen
,
Ashutosh Kumar
,
Rohit Girdhar
,
David Harwath
,
Kristen Grauman
PDF
Cite
InstanceDiffusion: Instance-level Control for Image Generation
SOTA instance-conditioned diffusion model for image generation.
Xudong Wang
,
Trevor Darrell
,
Sai Saketh Rambhatla
,
Rohit Girdhar
,
Ishan Misra
PDF
Cite
Code
Generating Illustrated Instructions
Introducing a new task of generating instructions for the task you want to solve with illustrations, and a LLM + Diffusion model based solution.
Sachit Menon
,
Ishan Misra
,
Rohit Girdhar
PDF
Cite
Code
VideoCutLER: Surprisingly Simple Unsupervised Video Instance Segmentation
SOTA unsupervised video segmentation using CutLER.
Xudong Wang
,
Ishan Misra
,
Ziyun Zeng
,
Rohit Girdhar
,
Trevor Darrell
PDF
Cite
Code
Motion-Conditioned Image Animation for Video Editing
Image animation FTW again! SOTA video editing results by animating the first frame with motion conditioning.
Wilson Yan
,
Andrew Brown
,
Pieter Abbeel
,
Rohit Girdhar
,
Samaneh Azadi
PDF
Cite
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
A simple and effective approach to high-quality video generation by learning to animate high quality images.
Rohit Girdhar
,
Mannat Singh
,
Andrew Brown
,
Quentin Duval
,
Samaneh Azadi
,
Sai Saketh Rambhatla
,
Akbar Shah
,
Xi Yin
,
Devi Parikh
,
Ishan Misra
PDF
Cite
Demo
ImageBind: One Embedding Space To Bind Them All
One embedding space for 6 different modalities, enables zero-shot recognition on all modalities!
Rohit Girdhar
,
Alaaeldin El-Nouby
,
Zhuang Liu
,
Mannat Singh
,
Kalyan Vasudev Alwala
,
Armand Joulin
,
Ishan Misra
PDF
Cite
Video
Code
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Scaling up MAE pre-pretraining, followed by weakly supervised pretraining, leads to strong representations.
Mannat Singh
,
Quentin Duval
,
Kalyan Vasudev Alwala
,
Haoqi Fan
,
Vaibhav Aggarwal
,
Aaron Adcock
,
Armand Joulin
,
Piotr Dollár
,
Christoph Feichtenhofer
,
Ross Girshick
,
Rohit Girdhar
,
Ishan Misra
PDF
Cite
Code
CutLER: Cut and Learn for Unsupervised Object Detection and Instance Segmentation
Discovering objects using DINO features, and learning an unsupervised detection + segmentation model
Xudong Wang
,
Rohit Girdhar
,
Stella X. Yu
,
Ishan Misra
PDF
Cite
Code
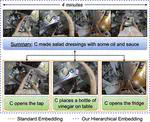
HierVL: Learning Hierarchical Video-Language Embeddings
Video-language embeddings are a promising avenue for injecting semantics into visual representations, but existing methods capture only short-term associations between seconds-long video clips and their accompanying text. We propose HierVL, a novel hierarchical video-language embedding that simultaneously accounts for both long-term and short-term associations.
Kumar Ashutosh
,
Rohit Girdhar
,
Lorenzo Torresani
,
Kristen Grauman
PDF
Cite
Video
Code
Learning Video Representations from Large Language Models
Leveraging LLMs to auto-annotate videos for representation learning.
Yue Zhao
,
Ishan Misra
,
Philipp Krähenbühl
,
Rohit Girdhar
PDF
Cite
Colab
Code
Omnivore: A Single Model for Many Visual Modalities
A single model for images, video and single-view 3D.
Rohit Girdhar
,
Mannat Singh
,
Nikhila Ravi
,
Laurens van der Maaten
,
Armand Joulin
,
Ishan Misra
PDF
Cite
Code
OmniMAE: Single Model Masked Pretraining on Images and Videos
Single self-supervised representation for images and videos.
Rohit Girdhar
,
Alaaeldin El-Nouby
,
Mannat Singh
,
Kalyan Vasudev Alwala
,
Armand Joulin
,
Ishan Misra
PDF
Cite
Video
Code
Ego4D: Around the World in 3,000 Hours of Egocentric Video
The largest egocentric video dataset.
Kristen Grauman
,
Andrew Westbury
,
Rohit Girdhar
,
et al
PDF
Cite
Video
Code
Detecting Twenty-thousand Classes using Image-level Supervision
Leverages image classification data to build an object detector
Xingyi Zhou
,
Rohit Girdhar
,
Armand Joulin
,
Philipp Krähenbühl
,
Ishan Misra
PDF
Cite
Colab
Code
Mask2Former for Video Instance Segmentation
SOTA video segmentation using Mask2Former.
Bowen Cheng
,
Anwesa Choudhuri
,
Ishan Misra
,
Alexander Kirillov
,
Rohit Girdhar
,
Alexander G. Schwing
PDF
Cite
Code
Masked-attention Mask Transformer for Universal Image Segmentation
Single architecture state-of-the-art in instance, semantic and panoptic segmentation.
Bowen Cheng
,
Ishan Misra
,
Alexander G. Schwing
,
Alexander Kirillov
,
Rohit Girdhar
PDF
Cite
Code
3DETR: An End-to-End Transformer Model for 3D Object Detection
First Transformer based detection architecture for 3D data.
Ishan Misra
,
Rohit Girdhar
,
Armand Joulin
PDF
Cite
Code
Anticipative Video Transformer
An autoregressive video transformer architecture for action anticipation in videos.
Rohit Girdhar
,
Kristen Grauman
PDF
Cite
Code
Self-Supervised Pretraining of 3D Features on any Point-Cloud
SOTA 3D detection/segmentation results by learning contrastive representations on 3D data
Zaiwei Zhang
,
Rohit Girdhar
,
Armand Joulin
,
Ishan Misra
PDF
Cite
Code
3D Spatial Recognition without Spatially Labeled 3D
WyPR can detect and segment objects in a 3D scene without needing any spatial labels at all!
Zhongzheng Ren
,
Ishan Misra
,
Alexander G. Schwing
,
Rohit Girdhar
PDF
Cite
Slides
Code
Physical Reasoning Using Dynamics Aware Embeddings
Self-supervised representations for physical reasoning.
Eltayeb Ahmed
,
Anton Bakhtin
,
Laurens van der Maaten
,
Rohit Girdhar
PDF
Cite
Code
Forward Prediction for Physical Reasoning
Forward prediction for PHYRE benchmark.
Rohit Girdhar
,
Laura Gustafson
,
Aaron Adcock
,
Laurens van der Maaten
PDF
Cite
Code
MetaPix: Few-Shot Video Retargeting
A dataset to evaluate temporal reasoning in video models.
Jessica Lee
,
Deva Ramanan
,
Rohit Girdhar
PDF
Cite
Slides
Video
Code
CATER: A diagnostic dataset for Compositional Actions and TEmporal Reasoning
A dataset to evaluate temporal reasoning in video models.
Rohit Girdhar
,
Deva Ramanan
PDF
Cite
Slides
Video
Code
DistInit: Learning Video Representations Without a Single Labeled Video
Distilling representations from image models to video models.
Rohit Girdhar
,
Du Tran
,
Lorenzo Torresani
,
Deva Ramanan
PDF
Cite
Video Action Transformer Network
Among the first applications of Transformers to model videos. SOTA results: close 2nd at AVA Challenge, CVPR'18.
Rohit Girdhar
,
João Carreira
,
Carl Doersch
,
Andrew Zisserman
PDF
Cite
Video
Detect-and-Track: Efficient Pose Estimation in Videos
Human keypoint tracking approach that ranked first in ICCV 2017 PoseTrack keypoint tracking challenge!
Rohit Girdhar
,
Georgia Gkioxari
,
Lorenzo Torresani
,
Manohar Paluri
,
Du Tran
PDF
Cite
Code
Attentional Pooling for Action Recognition
Among the first applications of attention for contemporary video/action understanding.
Rohit Girdhar
,
Deva Ramanan
PDF
Cite
Code
ActionVLAD: Learning spatio-temporal aggregation for action classification
Aggregating visual features for action recognition.
Rohit Girdhar
,
Deva Ramanan
,
Abhinav Gupta
,
Josef Sivic
,
Bryan Russell
PDF
Cite
Video
Code
Learning a Predictable and Generative Vector Representation for Objects
A single embedding space, good for both generating and understanding 3D models
Rohit Girdhar
,
David F. Fouhey
,
Mikel Rodriguez
,
Abhinav Gupta
PDF
Cite
Video
Code
Binge Watching: Scaling Affordance Learning from Sitcoms
Learning how humans interact with their environment by watching TV.
Xiaolong Wang
,
Rohit Girdhar
,
Abhinav Gupta
PDF
Cite
Cite
×