Rohit Girdhar
Rohit Girdhar
Home
Projects
Light
Dark
Automatic
Selected
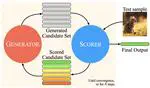
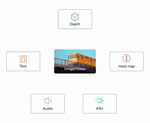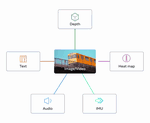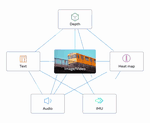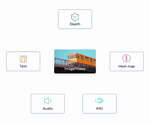
LLMs can see and hear without any training
Pure text-only LLMs can use off-the-shelf multimodal embedding models to do various multimodal tasks!
Kumar Ashutosh
,
Yossi Gandelsman
,
Xinlei Chen
,
Ishan Misra
,
Rohit Girdhar
PDF
Cite
Code
Movie Gen: A Cast of Media Foundation Models
State-of-the-Art Video (+Audio) Generation Model
MovieGen Team (Core-Contributor)
PDF
Cite
Video
The Llama 3 Herd of Models
State-of-the-Art open-source LLM with multimodal capabilities
Llama3 Team (Co-Lead the Video Recognition Efforts)
PDF
Cite
Code
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
A simple and effective approach to high-quality video generation by learning to animate high quality images.
Rohit Girdhar
,
Mannat Singh
,
Andrew Brown
,
Quentin Duval
,
Samaneh Azadi
,
Sai Saketh Rambhatla
,
Akbar Shah
,
Xi Yin
,
Devi Parikh
,
Ishan Misra
PDF
Cite
Demo
ImageBind: One Embedding Space To Bind Them All
One embedding space for 6 different modalities, enables zero-shot recognition on all modalities!
Rohit Girdhar
,
Alaaeldin El-Nouby
,
Zhuang Liu
,
Mannat Singh
,
Kalyan Vasudev Alwala
,
Armand Joulin
,
Ishan Misra
PDF
Cite
Video
Code
Learning Video Representations from Large Language Models
Leveraging LLMs to auto-annotate videos for representation learning.
Yue Zhao
,
Ishan Misra
,
Philipp Krähenbühl
,
Rohit Girdhar
PDF
Cite
Colab
Code
Omnivore: A Single Model for Many Visual Modalities
A single model for images, video and single-view 3D.
Rohit Girdhar
,
Mannat Singh
,
Nikhila Ravi
,
Laurens Van Der Maaten
,
Armand Joulin
,
Ishan Misra
PDF
Cite
Code
Ego4D: Around the World in 3,000 Hours of Egocentric Video
The largest egocentric video dataset.
Kristen Grauman
,
Andrew Westbury
,
Rohit Girdhar
,
Et Al
PDF
Cite
Video
Code
Masked-attention Mask Transformer for Universal Image Segmentation
Single architecture state-of-the-art in instance, semantic and panoptic segmentation.
Bowen Cheng
,
Ishan Misra
,
Alexander G. Schwing
,
Alexander Kirillov
,
Rohit Girdhar
PDF
Cite
Code
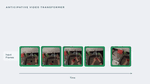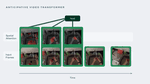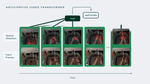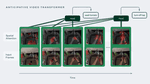
Anticipative Video Transformer
An autoregressive video transformer architecture for action anticipation in videos.
Rohit Girdhar
,
Kristen Grauman
PDF
Cite
Code
»
Cite
×