Rohit Girdhar
Rohit Girdhar
Home
Projects
Light
Dark
Automatic
Paper-Journal
Human detectors are surprisingly powerful reward models
Using human detection confidence as a simple yet effective reward model to improve human motion in video generation.
Kumar Ashutosh
,
Xudong Wang
,
Xi Yin
,
Kristen Grauman
,
Adam Polyak
,
Ishan Misra
,
Rohit Girdhar
PDF
Cite
Video
Toward Diffusible High-Dimensional Latent Spaces: A Frequency Perspective
Introducing FreqWarm, a plug-and-play frequency warm-up curriculum that improves high-dimensional latent diffusion by increasing early-stage exposure to high-frequency signals.
Bolin Lai
,
Xudong Wang
,
Saketh Rambhatla
,
James M. Rehg
,
Zsolt Kira
,
Rohit Girdhar
,
Ishan Misra
PDF
Cite
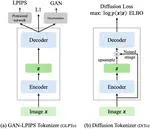
Diffusion Autoencoders are Scalable Image Tokenizers
Simplified image tokenization using diffusion
Yinbo Chen
,
Rohit Girdhar
,
Xiaolong Wang
,
Sai Saketh Rambhatla
,
Ishan Misra
PDF
Cite
Code
LLMs can see and hear without any training
Pure text-only LLMs can use off-the-shelf multimodal embedding models to do various multimodal tasks!
Kumar Ashutosh
,
Yossi Gandelsman
,
Xinlei Chen
,
Ishan Misra
,
Rohit Girdhar
PDF
Cite
Code
MotiF: Making Text Count in Image Animation with Motion Focal Loss
Using flow to improve motion in video generation
Shijie Wang
,
Samaneh Azadi
,
Rohit Girdhar
,
Saketh Rambhatla
,
Chen Sun
,
Xi Yin
PDF
Cite
Movie Gen: A Cast of Media Foundation Models
State-of-the-Art Video (+Audio) Generation Model
MovieGen Team (Core-Contributor)
PDF
Cite
Video
The Llama 3 Herd of Models
State-of-the-Art open-source LLM with multimodal capabilities
Llama3 Team (Co-Lead the Video Recognition Efforts)
PDF
Cite
Code
Motion-Conditioned Image Animation for Video Editing
Image animation FTW again! SOTA video editing results by animating the first frame with motion conditioning.
Wilson Yan
,
Andrew Brown
,
Pieter Abbeel
,
Rohit Girdhar
,
Samaneh Azadi
PDF
Cite
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
A simple and effective approach to high-quality video generation by learning to animate high quality images.
Rohit Girdhar
,
Mannat Singh
,
Andrew Brown
,
Quentin Duval
,
Samaneh Azadi
,
Sai Saketh Rambhatla
,
Akbar Shah
,
Xi Yin
,
Devi Parikh
,
Ishan Misra
PDF
Cite
Demo
Mask2Former for Video Instance Segmentation
SOTA video segmentation using Mask2Former.
Bowen Cheng
,
Anwesa Choudhuri
,
Ishan Misra
,
Alexander Kirillov
,
Rohit Girdhar
,
Alexander G. Schwing
PDF
Cite
Code
Cite
×