Rohit Girdhar
Rohit Girdhar
Home
Projects
Light
Dark
Automatic
Multimodal
Generating Illustrated Instructions
Introducing a new task of generating instructions for the task you want to solve with illustrations, and a LLM + Diffusion model based solution.
Sachit Menon
,
Ishan Misra
,
Rohit Girdhar
PDF
Cite
Motion-Conditioned Image Animation for Video Editing
Image animation FTW again! SOTA video editing results by animating the first frame with motion conditioning.
Wilson Yan
,
Andrew Brown
,
Pieter Abbeel
,
Rohit Girdhar
,
Samaneh Azadi
PDF
Cite
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
A simple and effective approach to high-quality video generation by learning to animate high quality images.
Rohit Girdhar
,
Mannat Singh
,
Andrew Brown
,
Quentin Duval
,
Samaneh Azadi
,
Sai Saketh Rambhatla
,
Akbar Shah
,
Xi Yin
,
Devi Parikh
,
Ishan Misra
PDF
Cite
Demo
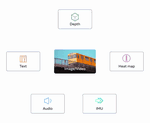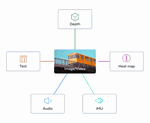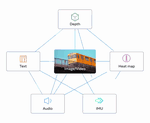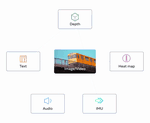
ImageBind: One Embedding Space To Bind Them All
One embedding space for 6 different modalities, enables zero-shot recognition on all modalities!
Rohit Girdhar
,
Alaaeldin El-Nouby
,
Zhuang Liu
,
Mannat Singh
,
Kalyan Vasudev Alwala
,
Armand Joulin
,
Ishan Misra
PDF
Cite
Video
Code
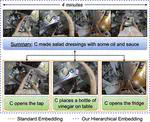
HierVL: Learning Hierarchical Video-Language Embeddings
Video-language embeddings are a promising avenue for injecting semantics into visual representations, but existing methods capture only short-term associations between seconds-long video clips and their accompanying text. We propose HierVL, a novel hierarchical video-language embedding that simultaneously accounts for both long-term and short-term associations.
Kumar Ashutosh
,
Rohit Girdhar
,
Lorenzo Torresani
,
Kristen Grauman
PDF
Cite
Video
Code
Learning Video Representations from Large Language Models
Leveraging LLMs to auto-annotate videos for representation learning.
Yue Zhao
,
Ishan Misra
,
Philipp Krähenbühl
,
Rohit Girdhar
PDF
Cite
Colab
Code
OmniMAE: Single Model Masked Pretraining on Images and Videos
Single self-supervised representation for images and videos.
Rohit Girdhar
,
Alaaeldin El-Nouby
,
Mannat Singh
,
Kalyan Vasudev Alwala
,
Armand Joulin
,
Ishan Misra
PDF
Cite
Video
Code
Omnivore: A Single Model for Many Visual Modalities
A single model for images, video and single-view 3D.
Rohit Girdhar
,
Mannat Singh
,
Nikhila Ravi
,
Laurens van der Maaten
,
Armand Joulin
,
Ishan Misra
PDF
Cite
Code
Ego4D: Around the World in 3,000 Hours of Egocentric Video
The largest egocentric video dataset.
Kristen Grauman
,
Andrew Westbury
,
Rohit Girdhar
,
et al
PDF
Cite
Video
Code
Cite
×